 Inglés
Inglés
Regresión logística en SPSS: odds ratio e interpretación paso a paso
¿Qué es la regresión logística y cuándo usarla?
La regresión logística binaria modela la relación entre una o varias variables independientes (continuas o categóricas) y una variable dependiente dicotómica. A diferencia de la regresión lineal, no predice un valor numérico continuo sino una probabilidad comprendida entre 0 y 1.
Ejemplos típicos en tesis: predecir si un paciente desarrolla una enfermedad (sí/no), si un estudiante aprueba o suspende, o si un cliente realiza una compra (sí/no).
— Fundamento teórico
¿Qué es la regresión logística y cuándo usarla?
La regresión logística binaria modela la relación entre una o varias variables independientes (continuas o categóricas) y una variable dependiente dicotómica. A diferencia de la regresión lineal, no predice un valor numérico continuo sino una probabilidad comprendida entre 0 y 1.
Ejemplos típicos en tesis: predecir si un paciente desarrolla una enfermedad (sí/no), si un estudiante aprueba o suspende, o si un cliente realiza una compra (sí/no).
|
¿Cuándo usar regresión logística en tu tesis? |
|
• La variable dependiente tiene exactamente 2 categorías (0/1, sí/no, caso/control). |
|
• Quieres cuantificar la influencia de cada predictor sobre la probabilidad del evento. |
|
• Necesitas controlar el efecto de variables de confusión de forma simultánea. |
|
• Tu objetivo es obtener un modelo de clasificación con capacidad predictiva medible. |
|
|
Supuestos del modelo: qué verificar antes de ejecutar en SPSS
Antes de interpretar ningún resultado, es imprescindible comprobar que se cumplen los supuestos del modelo. La regresión logística es más robusta que la regresión lineal —no exige normalidad de los residuos ni homocedasticidad— pero sí requiere:
• Ausencia de multicolinealidad: comprueba con el estadístico VIF (Factor de Inflación de la Varianza). Valores VIF > 10 indican problema.
• Tamaño muestral suficiente: se recomienda un mínimo de 10-20 casos por cada variable predictora incluida en el modelo.
• Linealidad en el logit: las variables continuas deben tener relación lineal con el logaritmo de los odds. Se verifica con el test de Box-Tidwell.
• Independencia de observaciones: las mediciones no deben estar correlacionadas entre sí (sin medidas repetidas sin el modelo mixto adecuado).
— Tutorial en SPSS
Paso a paso: regresión logística binaria en SPSS
Paso 1 — Acceder al procedimiento
En la barra de menú de SPSS ve a: Analizar → Regresión → Regresión logística binaria.
|
"menú regresión logística binaria SPSS ruta acceso tesis" |
.webp)
Captura 1. Ruta de acceso al procedimiento en SPSS 26/27.
Paso 2 — Configurar las variables
• Mueve la variable dependiente dicotómica (codificada 0/1) al campo Dependiente.
• Arrastra los predictores al bloque Covariables.
• Si tienes variables categóricas nominales, pulsa el botón Categórica y marca la codificación de referencia (indicador, primero/último).
• Método recomendado para tesis: Intro (todos los predictores juntos) o Pasos adelante LR (para selección de variables).
Paso 3 — Activar las opciones clave
En el botón Opciones activa:
• Estadísticos de clasificación (tabla de clasificación con el porcentaje global correcto).
• Correlaciones entre variables — detecta multicolinealidad incipiente.
• Iteraciones — útil para verificar que el modelo converge correctamente.
En el botón Guardar activa:
• Probabilidades pronosticadas — guarda los valores ajustados para análisis ROC posterior.
• Residuos de Cook — para detectar casos influyentes.
Paso 4 — Ejecutar y localizar los bloques de resultados
Tras pulsar Aceptar, SPSS generará varios bloques de salida. Los más importantes para tu tesis son:
• Bloque 0 — Modelo nulo (solo la constante): establece la línea de base de clasificación.
• Bloque 1 — Resumen del modelo: -2LL, R² de Cox y Snell, R² de Nagelkerke.
• Prueba ómnibus de coeficientes: contrasta si el modelo con predictores mejora significativamente al nulo.
• Variables en la ecuación: coeficientes B, error estándar, Wald, p y Exp(B).
• Tabla de clasificación: porcentaje de casos clasificados correctamente.
|
"tabla variables en la ecuación regresión logística SPSS odds ratio Exp B tesis" |
.webp)
.webp)
Captura 2. Tabla principal de resultados de regresión logística en SPSS con odds ratio Exp(B).
— Interpretación de resultados
Cómo interpretar los resultados de la regresión logística en SPSS
R² de Nagelkerke: bondad de ajuste
A diferencia de la regresión lineal, la regresión logística no tiene un R² convencional. El R² de Nagelkerke es el indicador de bondad de ajuste más utilizado en publicaciones científicas y tesis. Su interpretación es análoga: un valor de 0,40 indica que el modelo explica aproximadamente el 40% de la variabilidad de la variable dependiente.
|
Valores orientativos del R² de Nagelkerke |
|
• 0,10 – 0,20 → Ajuste débil (aceptable en estudios exploratorios con muchas variables). |
|
• 0,20 – 0,40 → Ajuste moderado (habitual en ciencias sociales y de la salud). |
|
• > 0,40 → Ajuste fuerte (frecuente en estudios con predictores muy controlados). |
|
Importante: siempre acompañar con la tabla de clasificación para validar. |
|
|
Odds ratio (Exp(B)): el coeficiente clave
El odds ratio (OR) es el estadístico central de la regresión logística y el que más aparece en tesis de ciencias de la salud, psicología y ciencias sociales. SPSS lo presenta bajo la columna Exp(B).
Regla de interpretación: un OR de 1,0 indica ausencia de efecto. Valores > 1,0 indican que al aumentar el predictor, aumentan las probabilidades del evento. Valores < 1,0 indican efecto protector.
|
Exp(B) |
Interpretación |
Ejemplo en tesis |
|
3,45 |
Por cada unidad más en el predictor, los odds del evento se multiplican por 3,45 |
Tener antecedentes familiares triplica las probabilidades de diagnóstico |
|
0,62 |
El predictor actúa como factor protector (reduce los odds en un 38%) |
Cada año adicional de escolaridad reduce las probabilidades de abandono escolar |
|
1,08 |
Efecto pequeño: los odds aumentan un 8% por unidad del predictor |
Cada punto de estrés percibido incrementa la probabilidad de burnout en un 8% |
|
1,00 |
Sin efecto significativo sobre la variable dependiente |
La variable no predice significativamente el evento estudiado |
Estadístico de Wald y significación
El estadístico de Wald contrasta si cada coeficiente B es significativamente distinto de cero. Un predictor se considera estadísticamente significativo cuando p < 0,05. Es el equivalente al estadístico t de la regresión lineal.
Recuerda que la significación estadística no implica relevancia práctica: un OR de 1,02 puede ser significativo con n > 10.000 pero carecer de utilidad clínica. Reporta siempre el OR junto con su intervalo de confianza al 95% (IC 95%).
Tabla de clasificación: capacidad predictiva del modelo
La tabla de clasificación muestra el porcentaje de casos que el modelo clasifica correctamente. Una clasificación global superior al 70-75% se considera aceptable en la mayoría de investigaciones.
|
"tabla clasificación regresión logística SPSS porcentaje correcto sensibilidad especificidad tesis" |
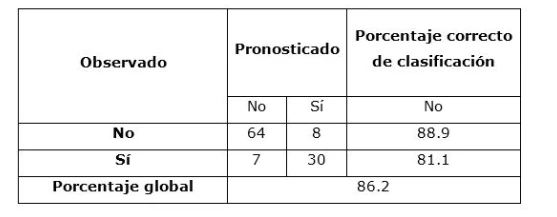
Captura 3. Tabla de clasificación en SPSS. El % global correcto valida la capacidad predictiva del modelo.
|
Truco profesional: combina regresión logística y curva ROC |
|
Guarda las probabilidades pronosticadas del modelo (botón Guardar > Probabilidades) y úsalas |
|
como variable de prueba en el análisis de curvas ROC. Así obtendrás el AUC del modelo completo, |
|
el punto de corte óptimo y la sensibilidad/especificidad asociadas — un estándar en tesis clínicas. |
|
|
— Ejemplo aplicado
Ejemplo práctico: regresión logística en una tesis de enfermería
Supón que estás investigando los factores que predicen la readmisión hospitalaria a los 30 días en pacientes con insuficiencia cardíaca. La variable dependiente es readmisión (0 = no, 1 = sí) y los predictores son edad, número de comorbilidades, nivel de hemoglobina y soporte social percibido.
|
Variable |
B |
E.T. |
Wald |
Sig. |
Exp(B) |
IC 95% |
|
Edad (años) |
0,042 |
0,018 |
5,44 |
0,020 |
1,043 |
1,007 – 1,081 |
|
N.º comorbilidades |
0,381 |
0,124 |
9,43 |
0,002 |
1,464 |
1,147 – 1,869 |
|
Hemoglobina (g/dl) |
−0,213 |
0,087 |
5,98 |
0,014 |
0,808 |
0,682 – 0,957 |
|
Soporte social |
−0,156 |
0,071 |
4,82 |
0,028 |
0,856 |
0,745 – 0,983 |
|
Constante |
−2,104 |
0,843 |
6,22 |
0,013 |
0,122 |
— |
Interpretación sintética para la sección de Resultados del TFM:
El modelo de regresión logística fue estadísticamente significativo (χ² = 38,4; gl = 4; p < 0,001) y explicó entre el 22,1% (R² Cox-Snell) y el 31,8% (R² Nagelkerke) de la varianza de la readmisión. La clasificación global correcta fue del 74,3%.
La edad (OR = 1,043; IC95%: 1,007–1,081; p = 0,020) y el número de comorbilidades (OR = 1,464; IC95%: 1,147–1,869; p = 0,002) se asociaron positivamente con la readmisión. Por el contrario, niveles más altos de hemoglobina (OR = 0,808; p = 0,014) y mayor soporte social percibido (OR = 0,856; p = 0,028) actuaron como factores protectores.
— Redacción para tesis
Cómo reportar la regresión logística en tu TFG o TFM
La sección de Resultados de una tesis debe incluir, como mínimo:
• La significación del modelo completo mediante la prueba ómnibus (χ², gl, p).
• Los valores de R² de Cox-Snell y de Nagelkerke.
• La tabla de clasificación con el porcentaje global correcto.
• Para cada predictor significativo: B, E.T., Wald, p, Exp(B) e IC al 95% de Exp(B).
Nota metodológica: en la sección de Método debe quedar explícito el criterio de inclusión/exclusión de variables, si se usó un método de entrada por pasos o simultáneo, y la verificación de los supuestos.
Errores frecuentes en tesis al usar regresión logística en SPSS
|
Evita estos errores comunes |
|
1. Codificar la variable dependiente como texto (Sí/No) en lugar de 0/1 — SPSS tomará como evento la categoría ordenada mayor, lo que puede invertir el sentido del OR. |
|
2. Incluir demasiados predictores con muestra pequeña — regla práctica: mínimo 10 casos del grupo minoritario por predictor. |
|
3. Reportar solo p-valores sin el IC 95% del OR — los comités de tesis y revisores cada vez exigen más el intervalo. |
|
4. Ignorar la multicolinealidad — si dos predictores correlacionan > 0,80, el modelo es inestable. |
|
5. Confundir OR con riesgo relativo (RR) — en estudios transversales o con prevalencias altas, el OR sobreestima el RR. |
|
|
— Preguntas frecuentes
Preguntas frecuentes sobre regresión logística en SPSS
¿Qué valor mínimo de R² de Nagelkerke es aceptable en una tesis?
No existe un umbral universal. En ciencias de la salud y psicología, valores entre 0,20 y 0,30 son habituales y aceptados. Un valor bajo no invalida el modelo si los odds ratio son coherentes con la teoría y la clasificación global es razonable.
¿Cuántos casos necesito para hacer una regresión logística en SPSS?
La regla empírica más citada es EPV ≥ 10 (Events Per Variable): al menos 10 casos del grupo menos frecuente por cada predictor incluido. Si la variable dependiente tiene un 20% de casos positivos y quieres incluir 5 predictores, necesitas al menos 250 casos totales.
¿Cuál es la diferencia entre regresión logística binaria, multinomial y ordinal?
La regresión logística binaria se usa con variables dependientes dicotómicas (2 categorías). La multinomial se aplica cuando la variable dependiente tiene 3 o más categorías sin orden (p. ej.: tipo de tratamiento). La ordinal se utiliza cuando las categorías tienen un orden natural (p. ej.: leve / moderado / grave). SPSS tiene procedimientos específicos para cada tipo.
¿Puedo usar regresión logística si mis variables independientes no son normales?
Sí. La regresión logística no asume normalidad de las variables independientes. Este es uno de sus principales ventajas frente a la discriminante lineal. La ausencia de normalidad en los predictores no viola ningún supuesto del modelo logístico.
|
¿Necesitas ayuda con la regresión logística de tu tesis?
Nuestro equipo de asesores estadísticos te guía desde la elección del modelo hasta la redacción de resultados para TFG, TFM y tesis doctorales. |
Artículos relacionados
• Curvas ROC en SPSS: cómo evaluar la capacidad diagnóstica del modelo logístico con AUC y punto de corte óptimo.
• Alfa de Cronbach en SPSS: fiabilidad de escalas y cuestionarios para tu TFG o TFM.
• ANOVA en SPSS: comparación de medias, prueba post hoc y tamaño del efecto.
• Análisis factorial en SPSS: validación de instrumentos con AFE y AFC.